Aujourd’hui, étant fournisseur de transit BGP pour des petits réseaux associatifs, je me rends compte que peu de gens qui débutent saisisse la différence entre iBGP et eBGP. Je vais donc essayer de l’expliquer le plus clairement possible.
En effet, ces opérateurs y vont progressivement, en ajoutant un routeur après l’autre. Avec un seul routeur, pas besoin d’iBGP, avec 2 ou plus, les choses changent.
Différence entre iBGP et eBGP
L’eBGP signifie Exterior Border Gateway Protocol, ou dit autrement, le protocol externe à votre AS. D’un point de vue d’un autre AS, votre AS apparaît simplement comme un AS unique. Même si votre réseau s’étend dans le monde entier (soyons fou ;))
L’iBGP signifie Interior Border Gateway Protocol, c’est BGP à l’intérieur de votre réseau. Son utilité est principalement d’aiguiller le trafic sortant de votre réseau vers vos bordures.
En iBGP, tout daemon BGP change son comportement sur 2 points très important pour la suite:
- Quand une route est apprise d’un routeur iBGP, le routeur cible ne la redistribue pas. Cela signifie que TOUT les routeurs doivent se voir en « full mesh ». (il existe des solutions pour éviter cela évoquer plus tard).
- l’attribut next hop n’est pas remplacé. Donc si le routeur B reçois une route du routeur A, le routeur B verra l’ip de bordure du routeur A (l’ip de l’IX, transitaire ou downstream) et non pas l’ip de l’interconnexion entre routeur A et B.
Un routeur bascule en mode iBGP dès que le même numéro d’AS est utilisé de chaque côté d’un peering bgp.
Exemple de réseau iBGP
Dans la suite de l’article, je vais expliquer les différentes topologies iBGP possible à ma connaissance. Afin d’être claire, je vais m’appuyer sur un schéma de réseau simple et j’y ferais référence tout le long. Je vous conseil donc de le garder à l’œil pour la suite.
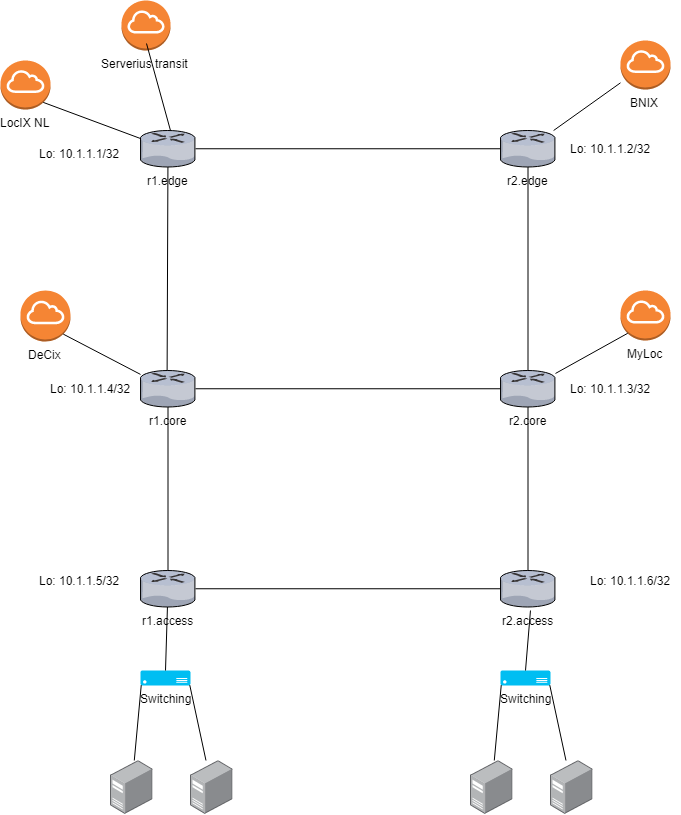
Ip de loopbacks
Pour commencer, je vais aborder, les ip de loopbacks. Pourquoi les utilise-t-on ? Si on monte nos sessions BGP sur base de chaque « LIEN », cela représente une grande quantité de sessions à gérer, de plus les ip peuvent être indisponible si les interfaces se coupent.
Pour connecter 2 routeurs en BGP via ces ip, nous utiliserons l’attribut multihop du daemon bgp.
OSPF
Je vais ici aborder l’intérêt d’OSPF dans un backbone iBGP, je ne parlerai pas spécifiquement de la gestion des aires, (area). Nous considérerons que tout se trouve dans l’aire 0 pour les connaisseurs ;).
Dans le setup ci-dessus, OSPF va tout d’abord être utilisé pour faire des annonces des loopbacks et permettre la connexion BGP. En effet, notre daemon BGP doit pouvoir joindre toutes les loopbacks avec lequel il sera interconnecté.
Sachant qu’on est en iBGP, tout nos routeurs doivent se voir en topologie fullmesh (chaque routeur doit peer les 5 autres soit plus de 30 sessions).
Il faut aussi exporter tout les réseaux de bordures dans l’OSPF (les /30 d’interco avec les transitaires et les réseaux des IX dans mon schéma), car souvenez vous, en ibgp, les routeurs ne remplacent pas la « next hop ».
Si dans mon exemple, r1.core reçois une route bnix, elle aura pour nexthop une ip dans le pool de bnix auquel r1.core n’est pas connecté directement.
Il interrogera donc une seconde fois sa table de routage (route récursive) et se rendra compte qu’il peut déposer le paquet sur r1.edge ou r2.core. Le même raisonnement se reproduira encore une fois pour atteindre r2.edge qui lui est directement connecté dans le réseau de l’IX.
Les routes récursives se font sur base d’OSPF. C’est donc son utilité principale. Il existe cependant une astuce quand vous n’avez que 2 routeurs par exemple. C’est le next hop self. BGP va alors remplacer la next hop par sa propre ip même entre 2 peer iBGP. On a donc plus besoin de propager les subnets d’interco des IX / transitaires via OSPF.
La technique du next hop self est parfois utilisée pour limiter le nombre de routes injectées dans ospf (en injectant que les loopbacks par exemple) car OSPF n’est pas fait pour accueillir une grande quantité de routes contrairement à BGP.
Pourquoi 2 protocoles de routages ?
BGP et OSPF ont chacun, leurs avantages, considérons dans notre exemple que le lien entre r2.edge et r2.core est rompu. Le trafic peut circuler par r1.edge et r1.core entre deux. Si nous montons des sessions bgp partout sans OSPF, cela veut dire que tout les routeurs de l’AS vont devoir converger à nouveau une fulltable et cela va entraîner des perturbations dans la force (euh dans le réseau). Dans le cas d’OSPF et les loopbacks, il n’y aura aucune convergence bgp
OSPF détectera et re routera la loopback par le second circuit le plus court disponible. Les sessions BGP ne décrocheront pas et il n’y aura pratiquement aucune coupure.
Ospf permet également d’assigner un poids sur chaque lien. C’est l’addition du poids de tous les liens qui aideront à trouver le chemin le plus court. De plus, comme il n’existe que quelques routes (et pas 800K), la prise de décision en est grandement accélérée.
Ospf gère donc l’état de votre réseau, et BGP l’état d’internet.
Enfin, l’ajout d’un lien reste plus simple lui aussi, OSPF ne nécessite pas de configuration complexe, mais juste de spécifier sur quelles interfaces il fonctionne.
Le fullmesh, vraiment? Imagine que ton réseau possède 500 routeurs?
Oui, en effet, la j’avoue, c’est complexe. Il existe pour ça une solution. l’introduction d’un route réflecteur (ou plusieurs pour la redondance)
Le route réflecteur possédera lui aussi une ip de loopback. Le but est de peer tout vos routeurs avec celui-ci et non plus de les peer ensemble. Celui-ci va alors générer une table de routage globale qui inclus la vue de tout le backbone. Cette table sera à nouveau réinjectée dans l’autre sens comme sa chaque routeur pourra choisir entre passer la route à son voisin ou la garder pour un de ses upstreams en y appliquant votre propre politique (hot potato, …)
Un route réflecteur ne route aucun paquets IP, son objectif est simplement de simplifier l’ajout de routeurs dans le backbone afin de permettre à l’infra d’être plus scalable.
Du coup, cette solution nous évite un grand nombre de sessions, par contre, je recommande vivement d’en avoir plusieurs réparti sur votre AS.
Et si je veux pas une seule table ?
Dans ce cas, il faut penser « fédération ». Vous créez plusieurs AS privés (que vos routeurs de bordure changeront en AS publique) chacun avec des core, de l’edge, de l’ospf et des route réflecteurs et vous les peerez vos réseaux entre eux. C’est une solution intéressante pour les réseaux intercontinentaux.
Et les annonces sortantes ?
Vos annonces publiques, faites les de vos routes réflecteurs, de cette manière si un routeur edge se retrouve isolé, il n’annonce plus rien. Cela ,vous garantis de garder un réseau stable.
Pour ce qui est des préfixes internes (les routes plus précises dans les quels vous adressez vos clients) vous pouvez les envoyer dans OSPF ou dans BGP. Si vous utilisez OSPF en mode « announce connected network », c’est le plus simple. Il ne faudra pas oublier de passer vos préfixes publics entres vos fédérations dans un tel cas.
Conclusion
Voilà, j’espère que cet article vous aide à y voir plus claire. Je n’entre pas dans les détails de l’implémentation et vous renvois à la documentation de votre matériel 😉
N’hésitez pas à poser vos questions / faire vos feedbacks en commentaires et à partager au maximum.
Très très intéressant les articles 😉
Cette article m’aide beaucoup merci de l’avoir rédigée